Your ‘Anonymous’ Browsing Data Isn’t Actually Anonymous
Credit to Author: Daniel Oberhaus| Date: Thu, 03 Aug 2017 13:00:00 +0000
In August 2016, a data broker received a phone call from a woman named Anna Rosenberg, who worked for a small startup in Tel Aviv. Rosenberg claimed she was training a neural network, a type of computing architecture inspired by the human brain, and needed a large set of browsing data to do so. The startup she was working for was well-funded and purchasing the data wouldn’t be a problem. But given the number of brokers out there, Rosenberg wasn’t going to purchase the browsing data from just anyone. She wanted a free trial.
A day after originally soliciting the data broker, Rosenberg received a phone call. A salesperson representing the broker gave Rosenberg the credentials she’d need to access the browsing data that was part of her free trial. The broker agreed to allow Rosenberg access to the complete browsing history of 3 million German users for one month, with the stipulation that for a part of this period, some of the browsing data would be collected live (that is, refreshed every day or so).
There was only one problem: Neither Anna Rosenberg nor the startup she claimed to represent existed.
Rosenberg was the alias of Svea Eckert, an undercover investigative journalist with the German media organization NDR who was looking into data sales practices and how difficult it is to de-anonymize the internet browsing data that is being collected and sold in bulk by third-party browser plugins.
“I was thinking maybe we’ll get a trial for three days or something,” Eckert told me last weekend at the Def Con hacking convention in Las Vegas, the first time this report had been presented outside of Germany. “The company we founded didn’t have a real address, it wasn’t registered. It was just a website and a LinkedIn account. We were really surprised they were willing to give us this data.”
After receiving her free trial data, Eckert partnered with Andreas Dewes, a data scientist who runs the company 7 Scientists, to see if they could identify individual users within the massive dataset. At first glance, the browsing data doesn’t look like much, just a bunch of URLs with timestamps.
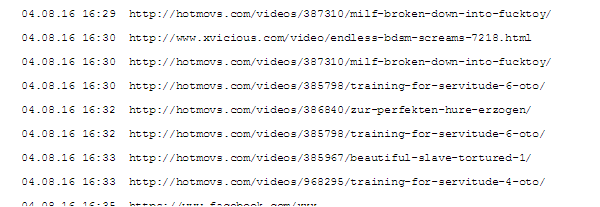
Eckert’s first task with the data was to find out if her browsing data was included in the dataset. To do this, she queried the data for the URL linked with her company’s login page, which generates a unique ID for each employee. Germany has a population of about 82 million, so the odds that Eckert herself was in browser data collected from 3 million Germans was small. Although it turned out her browser history wasn’t in the data set, by querying the data for her company’s login page Eckert discovered that a number of her colleagues were in the data by matching the unique login IDs from the company’s page to the individuals.
With this information, Eckert would’ve been able to see her colleagues’ entire browsing history for the last month. One of the colleagues included in the dataset was a close friend of hers, and she reached out to him to let him know that she had his browsing history. The question she had was which browser plugin was collecting and selling this data.
To answer this question, Eckert had her colleague delete one browser plugin every hour until he disappeared from the live data. On the seventh plugin, he disappeared. This suggested that the plugin collecting and selling his browser data was, ironically enough, called Web of Trust, which offers “free tools for safe search and web browsing.”
The troubling thing about Eckert and Dewes’ de-anonymization technique is that it can be used on anyone who has a public social media presence. For their report, Eckert and Dewes focused on Twitter and the German LinkedIn equivalent, Xing, to see if they could use these public profiles to de-anonymize public figures in the data.
When you click on your analytics page on Twitter, this brings you to a URL that includes your public Twitter handle—Xing has a similar feature. This means that Eckert and Dewes were able to query the database for these publicly available Twitter URLs for German politicians.
If the politicians were included in the dataset, the next step was to visit the Twitter profile of the politician and collect a few of the links they had recently posted. By using these links, coupled with the public Twitter URL, Eckert and Dewes were able to pull an individual’s entire month-long browsing history from the anonymous dataset.
As Dewes pointed out when he and I spoke at Def Con, it requires an astonishingly small amount of browsing information to identify an individual out of an anonymous dataset of 3 million people. Since everyone’s browsing habits are unique, it only takes about 10 website visits to create a “fingerprint” for an individual based on which websites they are visiting and when.
Moreover, since such a small number of websites are required to ID an individual, trying to trick this analysis technique by visiting a bunch of random websites to create noise won’t help, since only a handful of websites are needed to ID a person in the first place, Dewes added.
During their investigation, Eckert and Dewes managed to find a handful of politicians in the dataset. The web browsing habits of these public servants, such as the apparent kinky porn browsing habits of a Dutch judge, were laid bare for the researchers.
Valerie Wilms, a member of the German parliament, agreed to have her browsing habits revealed to her and was shocked by what the researchers were able to see. “This hurts,” Wilms said in the original NDR report. “It leaves people vulnerable for blackmailing.”
According to Eckert, the most worrisome part of collecting browsing data is that it is legal and relatively cheap to obtain. After contacting over 100 data brokers, Eckert said that the quoted prices she received for a month’s worth of browsing data ranged from 10,000 to 500,000 euros—chump change in the world of politics. When Eckert and Dewes approached the Web of Trust plugin responsible for the data sale, the company stated that the data sales were compliant with its terms of service and that company went to “great lengths” to anonymize the data.
As Eckert points out, it’s always important to read the terms of service and understand how a company says it uses its data. Even companies like Web of Trust, whose business model is built on safe and anonymous web browsing, are liable to unintentionally expose users browsing habits.
This also underscores the importance of net neutrality in America. In March, the US Congress voted to eliminate broadband privacy rules that would require Internet Service Providers to get customer consent before selling their browsing data. And as Eckert and Dewes’ investigation shows, this data can be easily obtained and used to pull individual’s browsing histories from the “anonymous” data.
“I have this feeling that data brokers don’t know what’s in the data,” Eckert said. “When I made these phone calls to inquire about buying data, they spoke as if they were selling stones or apples. These companies have lost their minds when it comes to data collection.”
Get six of our favorite Motherboard stories every day by signing up for our newsletter.